
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 클라우드 컴퓨팅
- Elasticsearch
- Spring
- 자료구조
- 로드밸런서
- aws
- springboot
- DFS
- 쿠버네티스
- 알고리즘
- 백트래킹
- Spring Data JPA
- 프로그래밍문제
- 머신러닝
- gcp
- 클라우드
- 스프링
- Apache Kafka
- JPA
- 스프링 부트
- 백준
- Kafka
- VPC
- Docker
- 오일러프로젝트
- 스프링부트
- Spring Boot
- 카프카
- 코드업
- 개발
- Today
- Total
GW LABS
Text Summarization (1) - TextRank 알고리즘 본문

문서를 요약하는 작업은 사람에게도 꾀 벅찬 작업이다. 문서의 정보손실을 최소화하면서 텍스트의 길이를 줄여야하기 때문에 우리는 문서를 요약할 때 문서에 없던 단어를 사용하기도하고, 자신만의 문체가 들어가기도 한다. 이런 문서요약 작업을 컴퓨터에게 시킬순 없을까? 시리즈로 문서요약 작업에 대해 알아보자!
1. 문서 요약의 종류
자동으로 문서를 요약할 때 보통 두 가지의 접근방법이 있다. 하나는 추출적 요약(extractive summarization)과 다른 하나는 추상적 요약(abstractive summarization)이다. 추출적 요약의 경우에는 본문에 존재하는 문장 중에서 중요한 문장을 추출하여 문서를 요약하는 기법이다. 추상적 요약은 사람이 문서를 요약하듯이 요약하는 방법이다. 따라서 문서에 없던 단어나 스타일이 반영될 수 있다.
2. 추출적 요약 기법, TextRank
텍스트 랭크는 구글의 페이지 랭크를 변형하여 문서를 요약하는 기법이다. 페이지 랭크는 문서를 그래프 구조로 표현한 상태에서 지속적으로 중요도를 업데이트하여 랭킹을 메기는 알고리즘이다.
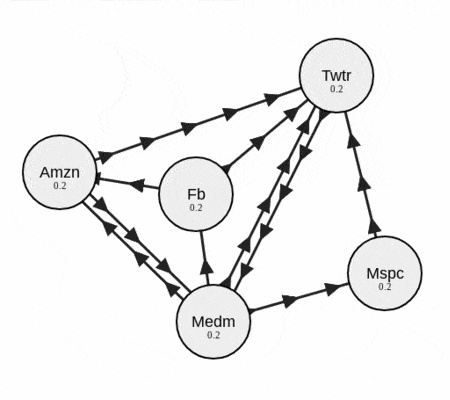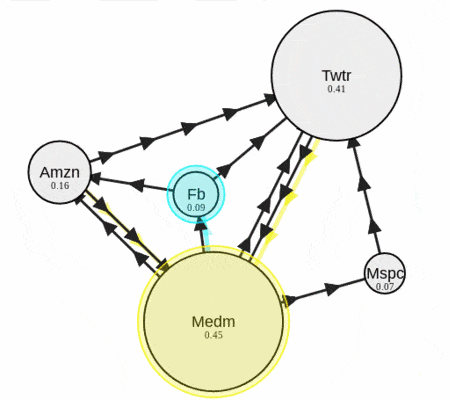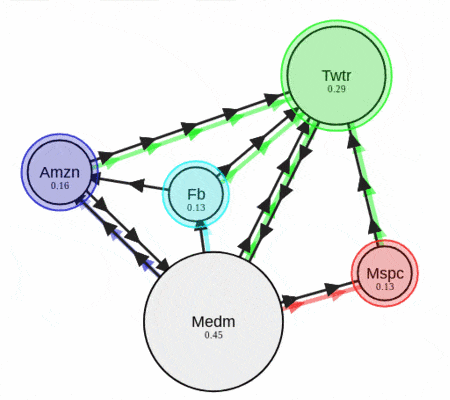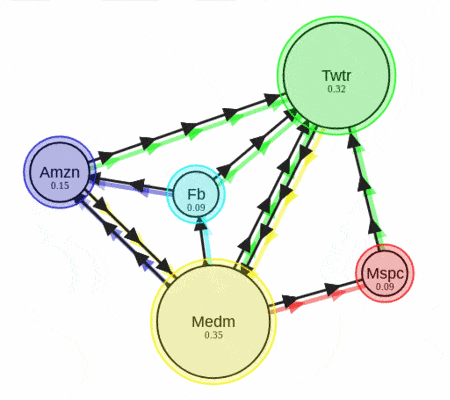
그림에서 보이는 것처럼 연결이 많이 된 문서의 중요도가 높다고 가정한 알고리즘이다. 텍스트 랭크는 이와 같은 페이지 랭크 알고리즘에 중요도를 자연어 처리에 사용되는 지표로 바꾸어 업데이트하는 알고리즘이라고 이해하면 되겠다. 주로 사용하는 기법은 TF-IDF 등이 있으나 이번 포스팅에서 구현한 소스에서는 자카드 지수를 이용해서 간단하게 구현했다.
3. 소스코드와 데모
class ProcessSentence {
constructor(sentence) {
this.sentence = sentence;
}
_tokenize() {
this.sentenceMetrics = this.sentence.split("\n");
}
getSentenceMetrics() {
this._tokenize();
return this.sentenceMetrics;
}
}원문 논문과 구현의 차이점이 있을 수 있으니 참고만 해주시길 부탁드리면서 코드를 설명해보겠다. 우선 우린 문서를 문장단위로 끊어줘야한다. Sentence 클래스는 입력으로 들어온 문장을 나눠주는 기능을 수행한다.
class WeightMetrics {
constructor(sentenceMetrics) {
this.sentenceMetrics = sentenceMetrics;
this.weightMetrics = new Array(sentenceMetrics.length).fill(0).map(() => new Array(sentenceMetrics.length).fill(0));
}
getWeightMetrics() {
this._update();
return this.weightMetrics;
}
_update() {
var weightsLength = this.weightMetrics.length;
for (var i = 0; i < weightsLength; i++) {
for (var j = 0; j < weightsLength; j++) {
var jaccardIndex = this._getJaccardIndex(
this._splitSentence(this.sentenceMetrics[i]), this._splitSentence(this.sentenceMetrics[j]));
if (!jaccardIndex) jaccardIndex = 0;
this.weightMetrics[i][j] = jaccardIndex;
}
}
}
_getJaccardIndex(s1, s2) {
var s1Set = new Set(s1);
var s2Set = new Set(s2);
var intersect = s1Set.intersection(s2Set);
var union = s1Set.union(s2Set);
return intersect.size / union.size;
}
_splitSentence(sentence) {
return sentence.split(" ");
}
}WeightMetrics 클래스에서는 문장 개수에 따라 N x N 가중치 행렬을 생성한다. 그리고 자카드 지수로 가중치 행렬을 업데이트 해준다. 참고로 문장을 스페이스 단위로 나누었을 때 교집합이 생길 확률은 거의 0에 수렴한다. 그래서 두 단어에서 연속된 3글자가 포함된다면 교집합이라고 가정했다.
class TextRank {
constructor(sentence) {
this.ps = new ProcessSentence(sentence);
this.weightMetrics = new WeightMetrics(this.ps.getSentenceMetrics());
this.weights = this.weightMetrics.getWeightMetrics();
this.score = new Float32Array(this.weights.length);
this._initRanking();
for (var i = 0; i < 20; i++)
this._updateLoop();
}
getSummarizedOneText() {
return this._top1();
}
getSummarizedThreeText() {
return this._top3();
}
_initRanking() {
var scoreLength = this.score.length;
for (var i = 0; i < scoreLength; i++) {
this.score[i] = (1 / scoreLength);
}
}
_updateLoop() {
var scoreLength = this.score.length;
for (var i = 0; i < scoreLength; i++) {
var tmp = 0;
for (var j = 0; j < scoreLength; j++) {
tmp += this.score[j] * this.weights[j][i];
}
this.score[i] = this.score[i] + tmp;
}
}
_top1() {
var maxScore = 0;
var maxIndex = 0;
for (var i = 0; i < this.score.length - 1; i++) {
if (maxScore < this.score[i]) {
maxScore = this.score[i];
maxIndex = i;
}
}
return this.weightMetrics.sentenceMetrics[maxIndex];
}
_top3() {
var ranking = new Array(this.score.length).fill(1);
for (var i = 0; i < this.score.length - 1; i++) {
for (var j = i + 1; j < this.score.length; j++) {
if (this.score[i] > this.score[j]) {
ranking[j]++;
}
else {
ranking[i]++;
}
}
}
console.log(this.score);
console.log(ranking);
var returnString = '';
for (var i = 1; i < 4; i++)
returnString += this.weightMetrics.sentenceMetrics[ranking.indexOf(i)] + "\n";
return returnString;
}
}마지막으로 TextRank 클래스에서 WeightMetrics를 통해 점수를 계산하게 된다. 가장 연관도가 높은 문장 1개와 1,2,3위를 이은 텍스트를 리턴하는 메소드를 구현했다.
데모를 실행시켜보면서 성능이 어떤지 확인해보자.
See the Pen Simple Javascript TextRank by Geon-Woo Kim (@youlive789) on CodePen.
4. 결언
딥러닝 시대에 아직도 추출적 기법인 TextRank가 중요한 이유는 여러가지가 있을 것이다. 첫째는 연산속도가 매우 빠르다는 점일 것이다. 머신러닝 기법에 비해 별도의 학습과정이 필요없다는 점이 매력적이다. 둘째는 자연어 처리에 사용되는 지표를 적용하기에도 쉽다. 이번 포스팅에서 데모로 구현한 부분을 TF-IDF와 형태소 분석을 결합시키면 한층 높은 성능을 얻을 수 있을 것이다. 세번째는 딥러닝 모델에 사용할 데이터의 전처리 용도로도 활용할 수 있다는 점이다.
GitHub
https://github.com/youlive789/simple_textrank_js
Reference
- ko.wikipedia.org/wiki/%EC%9E%90%EC%B9%B4%EB%93%9C_%EC%A7%80%EC%88%98
'MachineLearning' 카테고리의 다른 글
| Gemma3 270M으로 배우는 sLLM 파인튜닝과 Edge Device 서빙 전략 (0) | 2025.09.02 |
|---|---|
| XGBoost 회귀 완전 정복: RMSE, MAE부터 Tweedie와 Gamma까지 최적 Objective 선택법 (1) | 2025.08.25 |
| Text Summarization (3) - Transfer Learning (0) | 2020.09.18 |
| Text Summarization (2) - Sequence to Sequence (0) | 2020.08.31 |



