
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 로드밸런서
- Apache Kafka
- 쿠버네티스
- aws
- 알고리즘
- Spring Boot
- 자료구조
- 스프링
- 스프링부트
- 클라우드 컴퓨팅
- 백준
- VPC
- Spring Data JPA
- 스프링 부트
- 오일러프로젝트
- 카프카
- Docker
- 머신러닝
- 백트래킹
- DFS
- 프로그래밍문제
- Kafka
- 코드업
- Spring
- Elasticsearch
- 클라우드
- JPA
- springboot
- 개발
- gcp
- Today
- Total
GW LABS
Text Summarization (2) - Sequence to Sequence 본문

지난 포스팅
Text Summarization (1) - TextRank 알고리즘
지난 포스팅에서는 TextRank 알고리즘을 통해 머신러닝을 사용하지 않고 텍스트를 요약할 수 있는 방법을 알아봤다. 이번 포스팅에서는 딥러닝을 사용해서 문서를 요약하는 방법을 알아볼 것이다. 완전한 이해를 위해서는 방대한 선행지식이 필요하지만, 여기에서는 코드를 실행시켜보면서 어떤 방식으로 동작하는지 흐름을 파악해보자. 선행지식들을 배울 수 있는 곳들은 링크를 통해 남겨두겠다.
1. RNN(Recurrent Neural Network)
순환신경망(Recurrent Neural Network)는 인공신경망의 일종으로, 일렬로 늘어선 데이터, 시퀀스 데이터의 패턴을 학습하기 위해 고안되었다. 일렬로 늘어선 데이터들엔 어떤 것들이 있을까? 먼저 이 포스팅에서 다루는 텍스트가 있을 수 있겠다. 또한 주식 가격과 같은 시계열 데이터, 음성 데이터 등에도 사용된다.

더 자세한 사항은 이기창님의 RNN, LSTM 설명 포스팅을 읽어보자.
RNN과 LSTM을 이해해보자! · ratsgo's blog
이번 포스팅에서는 Recurrent Neural Networks(RNN)과 RNN의 일종인 Long Short-Term Memory models(LSTM)에 대해 알아보도록 하겠습니다. 우선 두 알고리즘의 개요를 간략히 언급한 뒤 foward, backward compute pass를 천천
ratsgo.github.io
2. Sequence to Sequence
시퀀스 투 시퀀스 모델 혹은 Encoder Decoder 모델이라고도 한다. 시퀀스 투 시퀀스 모델은 두 개의 RNN을 이어서 만든 네트워크이다. Encoder 측의 정보를 추출하여 Decoder를 통해 변환하는 과정이라고 생각하면 된다. Seq2Seq 모델은 신경망 기계번역(Neural Machine Translation)분야에서 놀라운 성능을 보여주면서 다양한 형태로 발전해왔다.
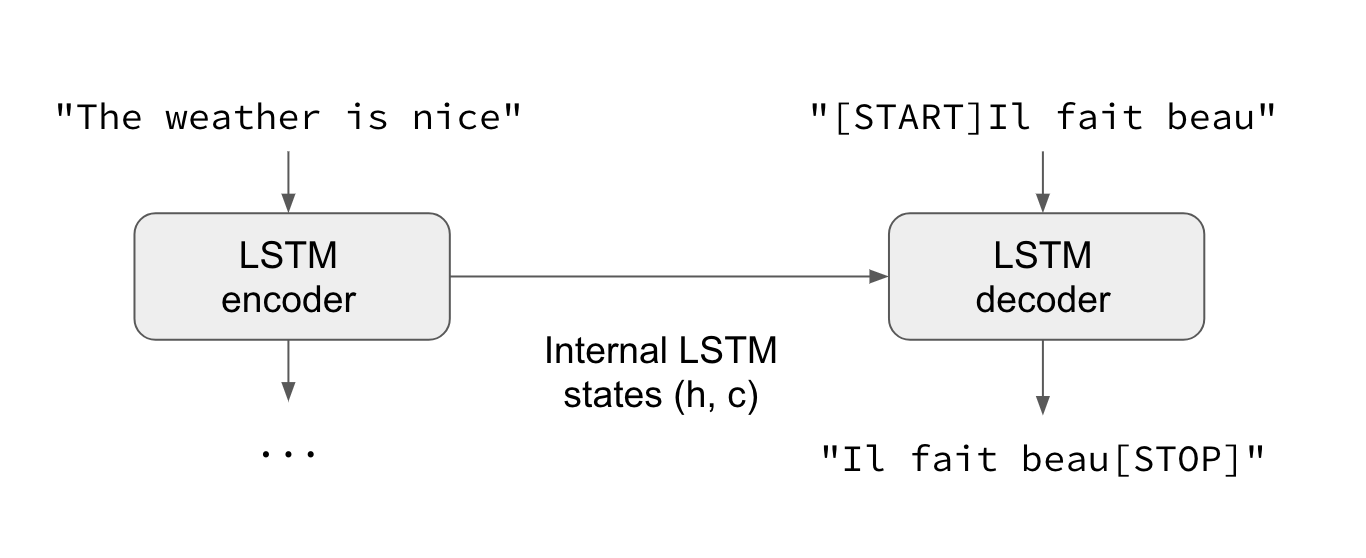
상세한 설명은 위키독스에서 볼 수 있다. 소스코드까지 첨부되어 있다.
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net
Seq2Seq 모델을 쉽게 공부하는 방법은 입력과 출력 기준으로 모델을 살펴보는 것이다. Seq2Seq로 문장요약 작업을 학습시키려면 입력으로 요약할 문장(encoder), 요약된 문장(decoder)을 넣어주고 출력으로 Seq2Seq 모델이 요약한 문장을 받는다.
3. 소스코드
youlive789/summarization_seq2seq
Text summarization example using sequence to sequence model implemented by tensorflow - youlive789/summarization_seq2seq
github.com
해당 깃헙소스에서 python main.py 명령어로 예제 요약작업을 볼 수 있다. 데이터는 이 블로그의 포스팅 4건을 이용해서 본문을 통해 제목을 요약해내는 방식으로 학습을 진행시켜보았다. 결과는 아래와 같다.
# https://gwlabs.tistory.com/26 포스팅을 요약
'[코드업', '3707]', '<UNK>', '<UNK>', '<PAD>', '<PAD>', '<PAD>', '<PAD>', '<PAD>', '<PAD>'
결과가 실망스러운데, 이유는 데이터가 너무 적고(블로그 포스팅 4건...) 추가적인 데이터 전처리가 필요하며 attention 매커니즘과 같은 Seq2Seq 성능을 높여주는 layer가 없기 때문이다. 그래도 본문을 통해 제목의 첫 부분을 맞춰내는 모습을 볼 수 있다.
4. 결언
처음부터 끝까지 단어 임베딩부터 Seq2Seq 모델을 구현하기까지의 모든 과정을 포스팅에 작성하진 않았다. 이 포스팅과 소스코드가 독자 여러분들이 딥러닝을 활용하여 문장요약을 어떤 방식으로 구성하면 될지 참고할 수 있는 자료가 되었으면 한다.
'MachineLearning' 카테고리의 다른 글
| Gemma3 270M으로 배우는 sLLM 파인튜닝과 Edge Device 서빙 전략 (0) | 2025.09.02 |
|---|---|
| XGBoost 회귀 완전 정복: RMSE, MAE부터 Tweedie와 Gamma까지 최적 Objective 선택법 (1) | 2025.08.25 |
| Text Summarization (3) - Transfer Learning (0) | 2020.09.18 |
| Text Summarization (1) - TextRank 알고리즘 (0) | 2020.08.13 |



